Équipe IMAGE - Le projet Pantheon
Équipe IMAGE - Le projet Pantheon
Ce tutoriel décrit une méthode pour classer des algorithmes de segmentation d'images selon leurs performances. L'originalité de la méthode proposée est de prendre en compte la tâche de segmentation pour calculer les valeurs de performances et faire le classement. La méthode est décrite par le biais d'un exemple fil rouge.
L'évaluation des performances d'un algorithme est basée sur des mesures de distance entre des résultats de l'algorithme de segmentation et des segmentations de référence dites vérités terrain.
Les performances sont évaluées à l'aide de cinq indicateurs, quatre géométriques et un topologique. Chaque indicateur est mesuré par deux erreurs de différence entre les résultats de segmentation et les vérités terrain correspondantes. En fonction de la tâche de segmentation, la valeur de performance pour l'indicateur est calculée par un compromis entre les deux valeurs d'erreur. L'évaluateur doit choisir un type de compromis parmi les 6 possibles donnés dans la colonne de droite du tableau ci-dessous.
|
1. Précision de la détection.
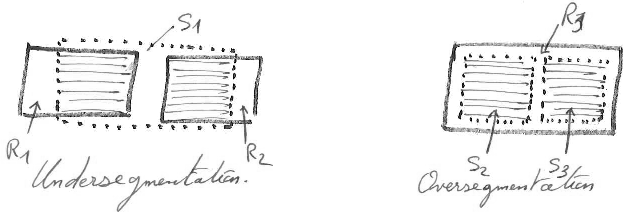
Cet indicateur mesure combien de régions de la vérité terrain ont été détectées par au moins un segment du résultat de segmentation. Un segment détecte une région si une partie du segment couvre une partie de la région. Il y a deux erreurs possibles. Les faux négatifs sont des régions de la vérité terrain qui ne sont pas couvertes par un segment. Les faux positifs sont des segments qui ne couvrent aucune région. Si l'indicateur de précision de la détection est jugé important pour une application donnée, alors il est aussi nécessaire de préciser laquelle des deux erreurs est la plus acceptable. Plus précisément, il est nécessaire de spécifier laquelle des propositions ci-à droite correspond le mieux à l'application.
|
| ||||||||||||
| 2. Cohérence de fragmentation.
Idéalement, chaque région devrait être détectée par un segment exactement et chaque segment devrait être détecté par une région exactement. Mais deux types d'erreur peuvent intervenir : la sur-segmentation correspond à la division d'une région en plusieurs segments, et la sous-segmentation correspond au regroupement de plusieurs régions dans un segment. Pour chaque application dans laquelle cet indicateur est jugé important, il est nécessaire de préciser quelle proposition parmi celles de droite correspond le plus aux objectifs de l'application :
|
| ||||||||||||
|
3. Précision des frontières.
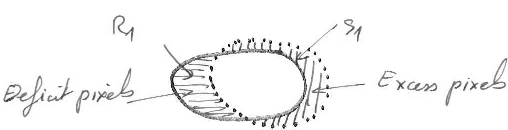
La précision des frontières est un aspect important pour beaucoup d'applications. La précision maximale est atteinte quand la surface des régions de la vérité terrain est couverte exactement par les segments correspondants. Les deux types d'erreur possibles sont l'excès de pixels quand les pixels des segments sont positionnés à l'extérieur de la région correspondante, et l'erreur de déficit de pixels quand les pixels des régions sont positionnés à l'extérieur du segment correspondant. L'évaluation de cet indicateur pour une application donnée doit être faite en fonction d'une des propositions ci-à droite.
|
| ||||||||||||
|
4. Respect de la forme.
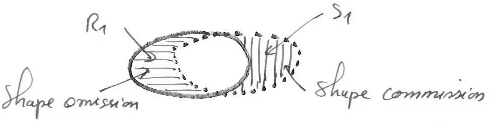
Le respect de la forme évalue de combien la forme des segments s'éloigne de la forme des régions correspondantes. Il mesure en quoi l'excès et le déficit de pixels affectent la forme des régions détectées : est-ce que les pixels mal segmentés sont plutôt répartis le long de la frontière ce qui modifie peu la forme ou au contraire forment plutôt une surface supplémentaire, ce qui modifie profondément la surface. Cet indicateur distingue les erreurs de forme dues à l'ajout de surface qui affecte l'extérieur de la région et celles dues à la perte de surface qui affecte l'intérieur de la région. Si le respect à la forme est un indicateur important pour une application, la préférence doit être donnée à l'une des propositions ci-à droite.
|
|
||||||||||||
|
5. Préservation de la topologie.
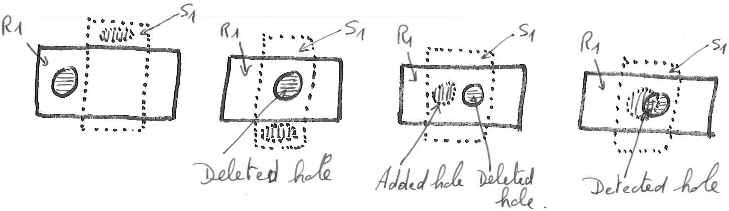
Le critère de topologie consiste à compter le nombre de trous. En effet, en 2D, deux régions sont topologiquement équivalentes si elles ont le même nombre de trous internes. Nous définissons un trou ajouté comme une composante connexe composée de pixels faux négatifs complètement à l'intérieur d'un segment. i.e., une composante connexe qui n'a qu'un segment voisin y compris le fond. Donc, un trou qui n'intersecte pas une région n'est pas un trou ajouté. De façon similaire, un trou supprimé est une composante connexe formée de pixels faux positifs qui sont complètement à l'intérieur d'une région. Les deux erreurs possibles sont l'addition de trous et la suppression de trous dans les régions détectées. Les propositions correspondantes sont données à droite.
|
|
La valeur de performance de chaque indicateur i résulte d'un compromis entre les deux erreurs antagonistes en fonction de ce que le développeur considère comme l'erreur la plus acceptable pour l'application parmi les 6 propositions :
Les deux erreurs sont acceptables. Cela correspond à exclure cet indicateur du classement :
indicateuri=0.
Les deux erreurs sont indésirables. Les deux erreurs sont pénalisées de la même façon :
| 0.5 0.5 |-1
indicateuri = 1 - | ----------- + ---------- |
| 1 - erreur2 1 - erreur1 |
Préférer l'erreur1 à l'erreur2. Cela correspond à pénaliser l'erreur2 deux fois plus que l'erreur1 :
| 0.8 0.2 |-1
indicateuri = 1 - | ----------- + ---------- |
| 1 - erreur2 1 - erreur1 |
Préférer l'erreur2 à l'erreur1. Au contraire, l'erreur1 est pénalisée deux fois plus que l'erreur2 :
| 0.2 0.8 |-1
indicateuri = 1 - | ----------- + ---------- |
| 1 - erreur2 1 - erreur1 |
Ne pas pénaliser les erreurs de type erreur1. Cela signifie d'utiliser seulement la valeur de l'erreur2 :
indicateuri = erreuri2
Ne pas pénaliser les erreurs de type erreur2. Cela signifie de n'utiliser que la valeur de l'erreur1 :
indicateuri = erreuri1
Finalement, le classement des algorithmes est fait en utilisant les cinq indicateurs calculés.
Après avoir précisé les erreurs les plus acceptables pour chaque indicateur, l'évaluateur doit donner les priorités sur ces indicateurs toujours en relation avec les besoins spécifiques de l'application ; les égalités sont possibles.
Pour effectuer le classement, les priorités sont d'abord converties en poids affectant chaque indicateur à partir d'une distribution uniforme de ces poids sur l'intervalle [0..1] selon l'approche "Rank Order Centroid". Chaque poids wi de l'indicateur i est obtenu à partir de la priorité j par :
wi = 1/n Sj=in{1/j}
par exemple, si n=5 alors w1=0.4567, w2=0.2567, w3=0.1567, w4=0.0900 et w5=0.0400.
Le classement est alors donné par la somme pondérée du rang rij de chaque algorithme i pour chaque indicateur j multiplié par le poids wj correspondant à la priorité j :
ri=Sj=1n{rij.wj}
|
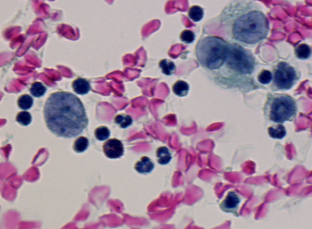
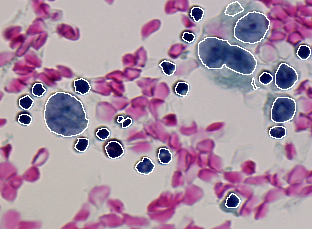
Il s'agit d'une application biologique dans le contexte du dépistage du cancer. Le but est d'assister les cytotechniciens à rechercher les cellules anormales ou suspectes sur des images. L'objectif spécifique de la segmentation d'images est de localiser chaque cellule de séreuse dans une région comme présenté dans la Figure 1.2. Ces régions seront ensuite données à un classifieur qui sera entraîné à identifier les types de cellules. La définition complète du problème nécessite de spécifier quelle erreur est la plus acceptable pour chacun des cinq indicateurs. Elles sont induites par les besoins de la classification :
|
|
|
Le script Pandore utilisé pour générer le résultat de l'évaluation des résultats de l'algorithme a001 est :
passesssegmentationalgorithm -v \
0 \
0.5 \
cytology/resultimages/a001 \
cytology/groundtruths \
/tmp/detail_errors_algo1.pan \
/tmp/total_errors_algo1.pan
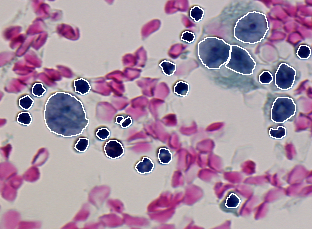
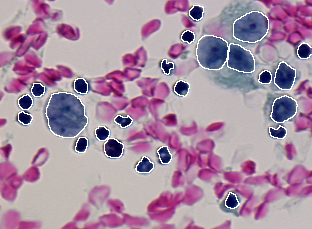
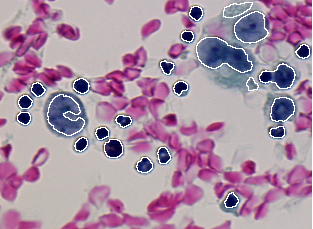
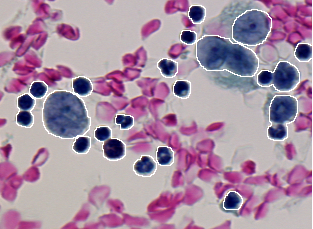
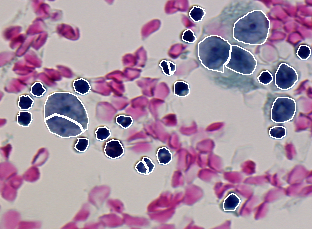
La table suivante donne les dix erreurs de différence entre le résultat de segmentation donné en Figure 2.3 et les deux vérités terrain données en Figure 2.1 et Figure 2.2. L'algorithme de mise en correspondance utilisé (type 0) autorise les correspondances de type une région avec n segments et un segment avec n régions. Le seuil de détection est fixé à 50% (0.50) dans le but de garder des cellules presque complètes. Un seuil plus faible aurait pour but d'accepter des cellules plus fragmentées qui nuiraient à leur identification ultérieure par le classifieur. Table 1. Les valeurs d'erreur résultant de la comparaison entre le résultat de segmentation donné dans la Figure 2.3 et les deux vérités terrain donnée en Figure 2.1 et 2.2. sont les suivantes.
L'interprétation des résultats est la suivante :
|
| |||||||||||||||||||||||||||||||
|
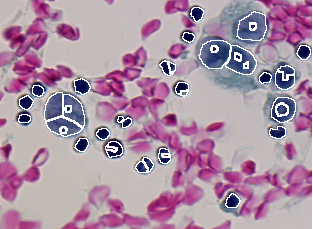
Nous supposons cinq algorithmes de segmentation d'images différents nommés respectivement A, B, C, D et E. Le résultat de segmentation de chacun de ces algorithmes sur l'image donnée Figure 3.1 sont présentés dans les Figures 3.2 to 3.6.
Les performances calculées pour les algorithmes sont données
dans la Table 2.
En utilisant les erreurs acceptables et les priorités données ci-dessous, on obtient le classement donné en Table 3 :
Table 3. Les valeurs d'indicateur des cinq algorithmes avec leur rang de performance pour les propositions {4, 2, 3}.
|
Le script Pandore utilisé pour le classement des algorithmes est :
pranksegmentationalgorithmsfromfolders \
0 0.5\
4 1 \
2 2 \
3 3 \
1 4 \
1 4 \
cytology/resultimages/ cytology/groundtruths \
/tmp/indicators2.pan /tmp/rank2.pan
L'ordre donné Table 3 indique que les deux algorithme B et D ont les mêmes meilleures performances pour cette application. B est meilleur en moyenne mais D est le plus perfomant sur le premier indicateur qui est le plus prioritaire. Pour cette application, l'un ou l'autre des deux algorithmes convient.
Les programmes d'évaluation et de claassement sont fournis avec la distribution de Pandore. Le code ci-dessous n'utilise pas Pandore. Il prend entrée des images de labels au format ppm. Néanmoins, le code peut être utilisé pour d'autres formats d'images, en changeant les fonctions de lecture d'images dans le fichier myinputoutput.h
make -f makefile.unix pranksegmentationalgorithmsfromfolders
nmake -f makefile.msdos pranksegmentationalgorithmsfromfolders.exe
pranksegmentationalgorithmsfromfolders [-v] matching_algorithm_id matching_threshold acceptable_error1 priority1 acceptable_error2 priority2 acceptable_error3 priority3 acceptable_error4 priority4 acceptable_error5 priority5 segmentation_result_path ground_truth_path result_indicators result_ranks
pranksegmentationalgorithmsfromfolders \
0 0.5\
4 1 \
2 2 \
3 3 \
1 4 \
1 4 \
./example/resultimages/ \
./example/groundtruths \
/tmp/indicators2.txt /tmp/rank2.txt